











イベント
Volta世代GPUにあわせて進化した「CUDA 9」の改良点とは? Tensor Coreへの対応やプログラミングモデルの拡張が鍵に
GTC 2017で大々的に発表された,NVIDIAの次世代アーキテクチャ「Volta」。そのVoltaを採用するGPU「GV100」のアーキテクチャについては,筆者による解説記事で詳しく説明しているが,その中で「Volta世代GPUに対応した新しいCUDA」として発表されたのが「CUDA 9」である。
このCUDA 9について詳しく解説するセッション「CUDA 9 and Beyond」が,北米時間2017年5月10日に行われた。セッションを担当したのは,「Mr.CUDA」の異名を持つMark Harris氏だ。CUDAの改良点だけでなく,Volta世代GPUのアーキテクチャに対する理解を深める内容のセッションをかいつまんでレポートしよう。
なお,本稿の一部は,Voltaのアーキテクチャを説明したセッション「Inside Volta」の内容を含んでいる。そのため,Voltaの解説記事と一部重複する部分があることをお断りしておきたい。
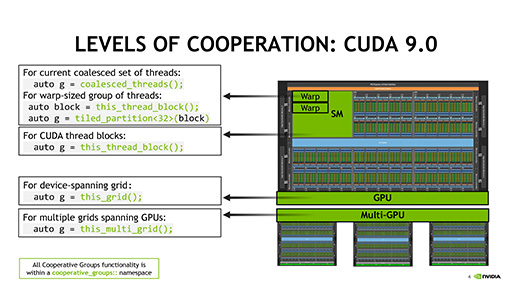
セッションの冒頭でHarris氏は,CUDA 9の新要素として,以下のスライドで示した4つの項目を挙げている。ただ,セッション内容は,この4項目にとらわれず,とくにNVIDIAがアピールしたいCUDA 9のポイントをピックアップして説明するという流れで行われたので,本稿でもそれに沿って話を進めたい。
新要素の1つめは,Volta世代GPUが搭載する「Tensor Core」への対応だ。
Tensor Coreとはなにかについては,アーキテクチャ解説記事で詳しく説明しているので,そちらを参照してもらうとして,ここでは簡単におさらいしておこう。
Tensor Coreとは,機械学習用AIで多用される大規模な行列計算や畳み込み演算に有用な専用演算ユニットである。
Tensor Coreが実行できる最も基本的な計算は,4×4要素の行列同士による積和算だ。Volta世代GPUでは,4×4要素の行列計算を2つセットにして,1つのWarp(※処理スレッドの実行単位)として扱えるようになっている。
また,Voltaでは,16×16要素の行列同士による積和算を,16個のWarpに分解して実行する。CUDA 9上では,「WMMA」(Warp Matrix Multiply and Accumulate)という新しいデータタイプ(※計算モデル)を利用することで,それ以上に巨大なサイズの行列計算を行うことも可能だという。もちろんその場合は,より多くのWarpに分解して処理する必要はあるが。
CUDA 9のWMMAを利用して巨大な行列計算を行ったときの処理能力を,Volta世代のGV100とPascal世代のGP100で比較した結果を,NVIDIAは公表している。アーキテクチャ解説記事でも掲載したものだが,あらためて示しておこう。Volta世代にはのGPUには,Pascal以前のGPUにはない行列計算専用プロセッサのTensor Coreがあるので,圧倒的な性能差が出るというわけだ。
Harris氏が解説したCUDA 9の新要素における2つめのポイントは,Volta世代よりも前,具体的にはKepler世代からPascal世代までのGPUにもメリットのある機能であるという。
その新要素は,「Warpを任意のサイズにグループ分けして,グループ間で同期をとる」というものだ。NVIDIA製GPUにおける一般的な1 Warpは,32個のデータスレッドからなるが,たとえば,それを4個のデータスレッドからなる8つのグループに分けることが可能になるという。
そしてグループに分けたデータスレッドは,任意のグループ同士で同期をとれる。グループごとに処理するGPUが異なる可能性のあるマルチGPU環境であっても,CUDA 9では明示的に同期がとれるようになったのだ。
CUDA 8までの場合,データスレッドの処理が終了した時点を暗黙の同期ポイントとしていたのだが,CUDA 9では,開発者が明示的に同期ポイントを記述できるようになった。
「CUDA 9でのグループ分けと同期の仕組みは,信頼性と安定性の高いデータ処理を行ううえで非常に重要だ」と,Harris氏は説明する。
一般的なGPUの命令実行は「Single Instruction Multiple Threads」(以下,SIMT),つまり,1つの命令で複数のデータスレッドを処理する形態だ。
また,異なるデータスレッドに同一メモリアドレスのデータが含まれていて,それらに対して処理が並列実行された場合,明示的な同期指定が行えなかったCUDA 8までは,想定した計算結果が得られなかったり,デバッグ困難なバグの原因となったりする可能性があった。それに対してCUDA 9では,明示的な同期の仕組みを導入することで,問題を解消できるというわけである。しかも,Pascal世代以前のGPUでも利用できるという点が大きなポイントといえよう。
Pascal世代以前のGPUでも使える同期の機能だが,本領を発揮するのは,やはりVolta世代GPUで利用するときだ。この本領発揮に当たる要素が,CUDA 9における3つめの大きなポイントだ。
Volta世代GPUでは,データスレッドの同期を取るだけでなく,データスレッド同士でメッセージをやりとりしたり,データを参照したりできるのである。
Harris氏が提示した極端にシンプルな例をもとに,この仕組みを説明してみよう。なお,開発者であれば一目で分かると思うが,これは説明のための概念的なプログラムコードであり,実際に動作するものではないのでご注意を。
A,B,Cという3つのリスト構造データがあり,AとCに対して何らかのGPGPU処理が行われているとしよう。処理自体が何かは問題ではないので,ここでは考慮しなくていい。
このAとCは,互いのメモリアドレスを参照し合うリスト構造のデータであり,そこに別のリスト構造データであるBを組み込みたいとしよう。リスト構造データの組み替えは,次のデータを指し示すポインタ(メモリアドレス値)の書き換えで行うので,ポインタの書き換えが他のGPGPU処理によって上書きされたりしないように,まずは書き換え対象であるAとCをロックする。
続いて,AとCの間にBが来るように,ポインタを書き換える。
書き換えが終わったら,AとCのロックを解除する。
こうした処理系を実現するには,データスレッドごとに異なる処理を行う必要がある。しかし,CUDAは本来,「そういう処理はしない」という前提で設計したプラットフォームだった。
Pascal世代以前のGPUでは,データスレッド32個からなるWarpは,1つのプログラムカウンタ(※スライドではPC)と1つのスタックポインタ(※スライドではS)で管理されていた。プログラムカウンタが示すメモリアドレスに格納されている命令を,複数のデータ――1 Warpなら32個のデータスレッド――に対して実行していたわけだ。
そのため,下のスライドに示したように,条件分岐プログラムの命令が実行されたとき,条件(if)を満たしたデータスレッドに対してだけ「A;」と「B;」の処理を実行し,それ以外の条件(else)を満たしたデータスレッドに対しては,「X;」と「Y;」の処理を行うというやり方で,スレッドごとに異なる処理を行っていた。
Warp内のデータスレッドは,共通のプログラムカウンタとスタックポインタで処理するので,各データスレッドに対して,個別の処理を適用するメカニズムがCUDAにはなかった。「A;」と「B;」で,あるいは「X;」と「Y;」で同期を取ることも,アーキテクチャ上できなかったのだ。
これに対してVolta世代GPUでは,Warp内のデータスレッドが個別のプログラムカウンタとスタックポインタを持てるように,GPUのアーキテクチャが改良された。
これにより,ifの条件を満たしたデータスレッド「A;」の処理が終わった段階で,ほかのデータスレッドと同期を取ったり,ほかのデータスレッドによる演算内容を参照したりといった異なる処理をさせることが可能になったと,Harris氏は説明していた。
なお,Harris氏が扱った話題は,プログラムの並列度を上げて性能を引き上げるためではなく,より複雑なプログラミングモデルを可能にするための拡張という点に注意してほしい。
そのほかにも,Volta世代GPUでCUDA 9を利用すると,同期時にデータスレッドの内容を任意に入れ替えたり,任意のルールに適合するスレッドだけに,特別な処理を行ったりといったことが可能になるという。こうした処理は,各データスレッドが個別のプログラムカウンタとスタックポインタを持ったことで実現できるようになったものだ。
CUDA 8からCUDA 9へのアップデートは,プログラミングモデルが大きく拡張されたこともあり,CUDAを扱う開発者に大きな影響を与えそうだ。
NVIDIA側の説明によると,CUDA 8以前のCUDAアプリは,CUDA 9で再コンパイルすることで,互換性を維持できるとのこと。とはいえ,今後はCUDA 9スタイルで開発することを,NVIDIAは強く推奨している。とくにデータスレッドを明示的に同期できる点は,CUDA 9にとってかなり重要な要素と位置付けているようだ。
では,そのCUDA 9がいつリリースされるのかだが,GTC 2017では未定とのことで,明言されなかった。しかし,Volta世代GPUのリリース時期に合わせて登場することは間違いないので,順当に考えれば2017年第3四半期頃になるだろう。
CUDAは,TeslaやQuadroといった製品群だけでなく,GeForceでも動作するわけだが,Volta世代GPUを採用すると思われる将来のGeForceで,CUDA 9の全機能が動作するのかは,現時点では分からないというのが正直なところだ。NVIDIAのスタッフに探りを入れてみても,「将来の製品に関する質問には回答しないよ」と,お決まりの台詞が返ってくるだけだった。
GeForceを使うCUDAユーザーが気になるポイントは,おそらく「GeForceのGPUにTensor Coreが載るかどうか」だろう。
Tensor Coreは事実上,機械学習用AIやコンピュータビジョン処理向けの演算ユニットという位置付けであり,現状ではDirectXやVulkanといった,業界標準の汎用グラフィックスAPIから利用する方法もない。たとえば,NVIDIA製GPUによるアクセラレーションが可能な物理シミュレーションエンジン「PhysX」で,Tensor Coreに対応することがあれば,ゲームで活用することもできなくはなさそうという程度である。
筆者は,短期的にはGeForceのGPUにTensor Coreを載せる可能性は低いと見ているが,さてどうなるだろうか。
一方で,Tensor Coreの搭載を除くと,VoltaとPascalのアーキテクチャにおける違いは,16nmプロセスと12nmプロセスといった物理設計以外に,今のところほとんどないようにも思える。Voltaの詳細が明らかになってくれば,Tensor Core以外の違いもクリアになるだろう。
NVIDIAは2017年4月に,ウルトラハイエンドのGPUとして,(GeForceの名は付かないが)「TITAN Xp」を発表済みである。また,2017年5月17日には,エントリー市場向けのPascal世代GPU「GeForce GT 1030」をリリースするなど,上から下までPascal系のラインナップが揃ったばかりだ。
そんな事情を考慮すると,Volta系GeForceがすぐに出てくる可能性はないと筆者は予想している。何か動きがあるとすれば,AMDの新世代GPU「Radeon RX Vega」が出てきたあとではないだろうか。
このCUDA 9について詳しく解説するセッション「CUDA 9 and Beyond」が,北米時間2017年5月10日に行われた。セッションを担当したのは,「Mr.CUDA」の異名を持つMark Harris氏だ。CUDAの改良点だけでなく,Volta世代GPUのアーキテクチャに対する理解を深める内容のセッションをかいつまんでレポートしよう。
 |
 |
なお,本稿の一部は,Voltaのアーキテクチャを説明したセッション「Inside Volta」の内容を含んでいる。そのため,Voltaの解説記事と一部重複する部分があることをお断りしておきたい。
CUDA 9の新要素 その1
Tensor Coreへの対応
セッションの冒頭でHarris氏は,CUDA 9の新要素として,以下のスライドで示した4つの項目を挙げている。ただ,セッション内容は,この4項目にとらわれず,とくにNVIDIAがアピールしたいCUDA 9のポイントをピックアップして説明するという流れで行われたので,本稿でもそれに沿って話を進めたい。
 |
 |
Tensor Coreとはなにかについては,アーキテクチャ解説記事で詳しく説明しているので,そちらを参照してもらうとして,ここでは簡単におさらいしておこう。
Tensor Coreとは,機械学習用AIで多用される大規模な行列計算や畳み込み演算に有用な専用演算ユニットである。
Tensor Coreが実行できる最も基本的な計算は,4×4要素の行列同士による積和算だ。Volta世代GPUでは,4×4要素の行列計算を2つセットにして,1つのWarp(※処理スレッドの実行単位)として扱えるようになっている。
 |
 |
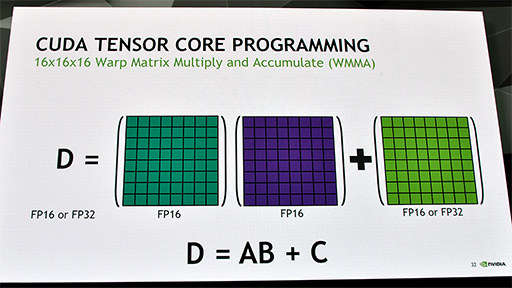
また,Voltaでは,16×16要素の行列同士による積和算を,16個のWarpに分解して実行する。CUDA 9上では,「WMMA」(Warp Matrix Multiply and Accumulate)という新しいデータタイプ(※計算モデル)を利用することで,それ以上に巨大なサイズの行列計算を行うことも可能だという。もちろんその場合は,より多くのWarpに分解して処理する必要はあるが。
 |
 |
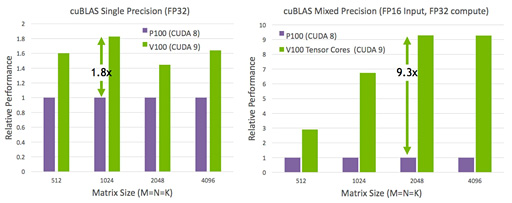
CUDA 9のWMMAを利用して巨大な行列計算を行ったときの処理能力を,Volta世代のGV100とPascal世代のGP100で比較した結果を,NVIDIAは公表している。アーキテクチャ解説記事でも掲載したものだが,あらためて示しておこう。Volta世代にはのGPUには,Pascal以前のGPUにはない行列計算専用プロセッサのTensor Coreがあるので,圧倒的な性能差が出るというわけだ。
 |
CUDA 9の新要素 その2
データスレッドの自由なグループ化
Harris氏が解説したCUDA 9の新要素における2つめのポイントは,Volta世代よりも前,具体的にはKepler世代からPascal世代までのGPUにもメリットのある機能であるという。
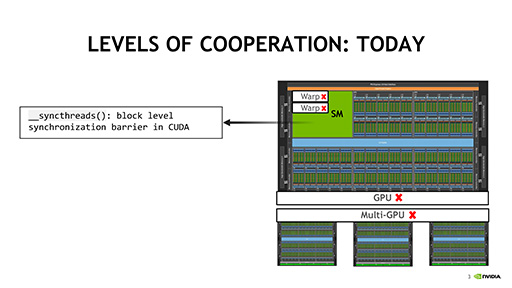
その新要素は,「Warpを任意のサイズにグループ分けして,グループ間で同期をとる」というものだ。NVIDIA製GPUにおける一般的な1 Warpは,32個のデータスレッドからなるが,たとえば,それを4個のデータスレッドからなる8つのグループに分けることが可能になるという。
 |
そしてグループに分けたデータスレッドは,任意のグループ同士で同期をとれる。グループごとに処理するGPUが異なる可能性のあるマルチGPU環境であっても,CUDA 9では明示的に同期がとれるようになったのだ。
CUDA 8までの場合,データスレッドの処理が終了した時点を暗黙の同期ポイントとしていたのだが,CUDA 9では,開発者が明示的に同期ポイントを記述できるようになった。
 |
 |
「CUDA 9でのグループ分けと同期の仕組みは,信頼性と安定性の高いデータ処理を行ううえで非常に重要だ」と,Harris氏は説明する。
一般的なGPUの命令実行は「Single Instruction Multiple Threads」(以下,SIMT),つまり,1つの命令で複数のデータスレッドを処理する形態だ。
また,異なるデータスレッドに同一メモリアドレスのデータが含まれていて,それらに対して処理が並列実行された場合,明示的な同期指定が行えなかったCUDA 8までは,想定した計算結果が得られなかったり,デバッグ困難なバグの原因となったりする可能性があった。それに対してCUDA 9では,明示的な同期の仕組みを導入することで,問題を解消できるというわけである。しかも,Pascal世代以前のGPUでも利用できるという点が大きなポイントといえよう。
 |
 |
 |
CUDA 9の新要素 その3
データスレッド間でデータの参照や書き換えを可能に
Pascal世代以前のGPUでも使える同期の機能だが,本領を発揮するのは,やはりVolta世代GPUで利用するときだ。この本領発揮に当たる要素が,CUDA 9における3つめの大きなポイントだ。
Volta世代GPUでは,データスレッドの同期を取るだけでなく,データスレッド同士でメッセージをやりとりしたり,データを参照したりできるのである。
Harris氏が提示した極端にシンプルな例をもとに,この仕組みを説明してみよう。なお,開発者であれば一目で分かると思うが,これは説明のための概念的なプログラムコードであり,実際に動作するものではないのでご注意を。
A,B,Cという3つのリスト構造データがあり,AとCに対して何らかのGPGPU処理が行われているとしよう。処理自体が何かは問題ではないので,ここでは考慮しなくていい。
このAとCは,互いのメモリアドレスを参照し合うリスト構造のデータであり,そこに別のリスト構造データであるBを組み込みたいとしよう。リスト構造データの組み替えは,次のデータを指し示すポインタ(メモリアドレス値)の書き換えで行うので,ポインタの書き換えが他のGPGPU処理によって上書きされたりしないように,まずは書き換え対象であるAとCをロックする。
 |
続いて,AとCの間にBが来るように,ポインタを書き換える。
 |
書き換えが終わったら,AとCのロックを解除する。
 |
こうした処理系を実現するには,データスレッドごとに異なる処理を行う必要がある。しかし,CUDAは本来,「そういう処理はしない」という前提で設計したプラットフォームだった。
Pascal世代以前のGPUでは,データスレッド32個からなるWarpは,1つのプログラムカウンタ(※スライドではPC)と1つのスタックポインタ(※スライドではS)で管理されていた。プログラムカウンタが示すメモリアドレスに格納されている命令を,複数のデータ――1 Warpなら32個のデータスレッド――に対して実行していたわけだ。
 |
そのため,下のスライドに示したように,条件分岐プログラムの命令が実行されたとき,条件(if)を満たしたデータスレッドに対してだけ「A;」と「B;」の処理を実行し,それ以外の条件(else)を満たしたデータスレッドに対しては,「X;」と「Y;」の処理を行うというやり方で,スレッドごとに異なる処理を行っていた。
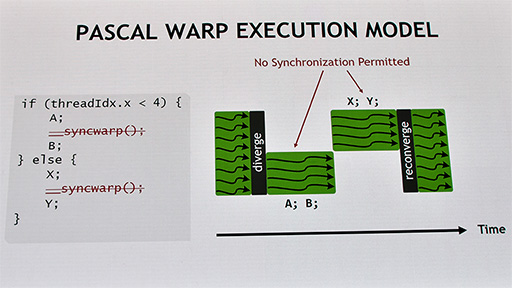 |
Warp内のデータスレッドは,共通のプログラムカウンタとスタックポインタで処理するので,各データスレッドに対して,個別の処理を適用するメカニズムがCUDAにはなかった。「A;」と「B;」で,あるいは「X;」と「Y;」で同期を取ることも,アーキテクチャ上できなかったのだ。
これに対してVolta世代GPUでは,Warp内のデータスレッドが個別のプログラムカウンタとスタックポインタを持てるように,GPUのアーキテクチャが改良された。
 |
これにより,ifの条件を満たしたデータスレッド「A;」の処理が終わった段階で,ほかのデータスレッドと同期を取ったり,ほかのデータスレッドによる演算内容を参照したりといった異なる処理をさせることが可能になったと,Harris氏は説明していた。
 |
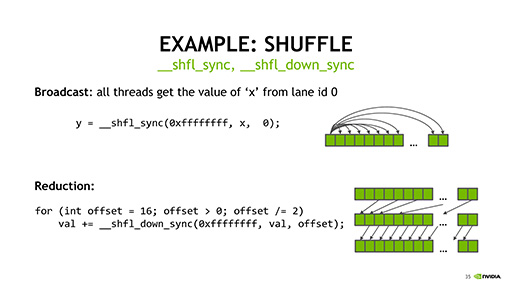
なお,Harris氏が扱った話題は,プログラムの並列度を上げて性能を引き上げるためではなく,より複雑なプログラミングモデルを可能にするための拡張という点に注意してほしい。
そのほかにも,Volta世代GPUでCUDA 9を利用すると,同期時にデータスレッドの内容を任意に入れ替えたり,任意のルールに適合するスレッドだけに,特別な処理を行ったりといったことが可能になるという。こうした処理は,各データスレッドが個別のプログラムカウンタとスタックポインタを持ったことで実現できるようになったものだ。
 |
 |
GeForce向けVoltaにTensor Coreは載るのか?
CUDA 8からCUDA 9へのアップデートは,プログラミングモデルが大きく拡張されたこともあり,CUDAを扱う開発者に大きな影響を与えそうだ。
NVIDIA側の説明によると,CUDA 8以前のCUDAアプリは,CUDA 9で再コンパイルすることで,互換性を維持できるとのこと。とはいえ,今後はCUDA 9スタイルで開発することを,NVIDIAは強く推奨している。とくにデータスレッドを明示的に同期できる点は,CUDA 9にとってかなり重要な要素と位置付けているようだ。
では,そのCUDA 9がいつリリースされるのかだが,GTC 2017では未定とのことで,明言されなかった。しかし,Volta世代GPUのリリース時期に合わせて登場することは間違いないので,順当に考えれば2017年第3四半期頃になるだろう。
CUDAは,TeslaやQuadroといった製品群だけでなく,GeForceでも動作するわけだが,Volta世代GPUを採用すると思われる将来のGeForceで,CUDA 9の全機能が動作するのかは,現時点では分からないというのが正直なところだ。NVIDIAのスタッフに探りを入れてみても,「将来の製品に関する質問には回答しないよ」と,お決まりの台詞が返ってくるだけだった。
 |
Tensor Coreは事実上,機械学習用AIやコンピュータビジョン処理向けの演算ユニットという位置付けであり,現状ではDirectXやVulkanといった,業界標準の汎用グラフィックスAPIから利用する方法もない。たとえば,NVIDIA製GPUによるアクセラレーションが可能な物理シミュレーションエンジン「PhysX」で,Tensor Coreに対応することがあれば,ゲームで活用することもできなくはなさそうという程度である。
筆者は,短期的にはGeForceのGPUにTensor Coreを載せる可能性は低いと見ているが,さてどうなるだろうか。
一方で,Tensor Coreの搭載を除くと,VoltaとPascalのアーキテクチャにおける違いは,16nmプロセスと12nmプロセスといった物理設計以外に,今のところほとんどないようにも思える。Voltaの詳細が明らかになってくれば,Tensor Core以外の違いもクリアになるだろう。
NVIDIAは2017年4月に,ウルトラハイエンドのGPUとして,(GeForceの名は付かないが)「TITAN Xp」を発表済みである。また,2017年5月17日には,エントリー市場向けのPascal世代GPU「GeForce GT 1030」をリリースするなど,上から下までPascal系のラインナップが揃ったばかりだ。
そんな事情を考慮すると,Volta系GeForceがすぐに出てくる可能性はないと筆者は予想している。何か動きがあるとすれば,AMDの新世代GPU「Radeon RX Vega」が出てきたあとではないだろうか。
- 関連タイトル:
 CUDA
CUDA
- 関連タイトル:NVIDIA RTX,Quadro,Tesla
- この記事のURL:
キーワード
- HARDWARE:CUDA
- GPU
- GeForce
- NVIDIA
- HARDWARE:NVIDIA RTX,Quadro,Tesla
- HARDWARE
- イベント
- ライター:西川善司
- GPU Technology Conference
- GTC 2017
Copyright(C)2010 NVIDIA Corporation
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー