











ニュース
スマホ向けゲームのグラフィックスを改善する「Tile Based Rendering」での新テクニックとは? ArmのGPUアーキテクトが語る
 |
氏によるセッションは,PCやゲーム機のGPUと比べて非力なスマートフォン向けSoC(System-on-a-Chip,タブレット端末や携帯ゲーム機も含む)のGPUに関する非常に興味深い内容だったので,本稿で解説したい。
 |
スマートフォン向けGPUに課せられた大きな縛り
スマートフォン向けSoCが搭載するGPUは,PCやゲーム機のGPUに比べれば性能が高くないことを,とくにハードウェアへの関心が強くないゲーマーでも,理解しているかもしれない。
スマートフォンで,リッチなグラフィックス表現のゲームを,長時間連続でプレイしていると,本体が熱を持ったり,フレームレートが低くなったりする症状を,目の当たりにしたことがあると思う。スマートフォンとPC,ゲーム機のマルチプラットフォームタイトルでは,スマートフォン版のグラフィックス表現があからさまに簡略化されていたり,解像度やフレームレートで明確な差を付けられていたりすることに,気付いたことのある人もいるだろう。
 |
ただ,メモリアクセスが遅いのは,CPUとGPUで同一メモリ空間を共有しているせいではない。据え置き型ゲーム機であるPlayStation 5は,CPUとGPUでGDDR6メモリを共有しているわけだが,メモリバス幅は256bit幅で,メモリバス帯域幅は450GB/s前後もある。高度なゲームグラフィックスを実現するのに,必要十分なスペックだ。
単体GPUやPS5に比べればあまり速くないCPU内蔵型GPUのメモリバスですら,メモリバス幅は128bitあり,メモリバス帯域幅は,DDR5-6000のデュアルチャネル時で100GB/s前後はある。
それに対して,多くのスマートフォン向けSoCのCPUとGPUは,メモリバスが64bit程度,メモリバス帯域幅は50GB/s前後しかない。しかも,メモリへアクセスすればするほど,バッテリー消費が増えていく。
そもそも,スマートフォン向けSoCは,3Dグラフィックスのゲームを動かすことには不向きなハードウェアなのだ。しかし,世界中の優秀な半導体エンジニアが生みだした高度な技術によって,ギリギリのバランスで実現しているわけである。
スマートフォン向けSoCにおける3Dグラフィックスの裏テーマ
スマートフォン向けSoCで,一番の命題となるのは,とにかく電力消費を少なくすることだ。仮に,CPUやGPUの処理能力に余裕があったとしても,与えられた電力予算を超えた動作は行えない。たとえば,CPU負荷が高くなれば多くの電力を消費するので,その間は,GPUの消費電力を抑制する必要があり,全力動作ができなくなることがある。ゲーム機やPCとはまったく異なるルールを課せられているわけだ。
Garcia氏によれば,現在の一般的なスマートフォン向けSoCにおいて,CPUとGPU,そしてメインメモリの電力予算=総消費電力は,3〜6Wの範囲であるという。
 |
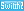
ここで厄介なのはメモリアクセスだ。次のスライドにもあるように,一般的なスマートフォン向けSoCにおいては,「80mW/GB/s」という目安がある。
 |
80mW/GB/sとは,1GB/sのメモリバス帯域幅を使用して,CPUまたはGPUがメモリアクセスを行った場合,1秒間に80mWの電力を消費するという意味だ。
先に,スマートフォン向けSoCのメモリバス帯域幅は約50GB/s程度と書いたが,50GB/sのメモリバス帯域幅を1秒間使用すると,80mW/GB/s×50GB/s=4000mW(=4W)となる。メモリアクセスだけで,1秒間に4Wもの電力を消費してしまう計算だ。
先述のとおり,CPUとGPU,メモリの総消費電力は,最大6W以下が求められるので,メモリアクセスを何度も行って電力を消費してしまえば,CPUとGPUとで使える電力は6−4Wで2W以下になってしまう。これでは,高度なリアルタイム3Dグラフィックス描画は無理だ。
メモリバス帯域幅の消費を節約する。つまり,事実上メモリアクセスの節約こそが,スマートフォン向けSoCでリアルタイム3Dグラフィックスの実現するときに,最も重要な裏テーマなのだ。
Tile Based Renderingとはなにか
 |
SRAMは,記憶保持にリフレッシュ(電荷補充)工程が不要なメモリであり,電荷補充が必要なメインメモリに使うDDR系DRAMと比べて,圧倒的に低遅延でメモリバス帯域幅も格段に広い特徴がある。キャッシュメモリやレジスタなどに採用される超高速メモリだ。
とても素晴らしいメモリなのだが,半導体の微細化に適さない面があり,大容量を搭載するには製造コストがかなり高くつく欠点がある。さらに,無理矢理大容量のSRAMを積んでも,消費電力が高くなってしまう。
というわけで,スマートフォン向けGPUでは,SRAMを使うにしてもなるべく少なく,それでいて十分なメモリアクセスの節約が行えるユニークなGPUアーキテクチャが望まれることとなった。
その要求に応えたのが,今でも多くのスマートフォン向けGPUが採用する「Tile Based Rendering」(TBR)と呼ばれる手法だ(関連記事)。
TBRは,Imagination Technologies(旧VideoLogic)で考案され,1996年登場のGPU「PowerVR」(PCX1)で初めて導入された。なおTBRは,今では,Apple独自SoCである「Apple M」シリーズの内蔵GPUにも採用されている。
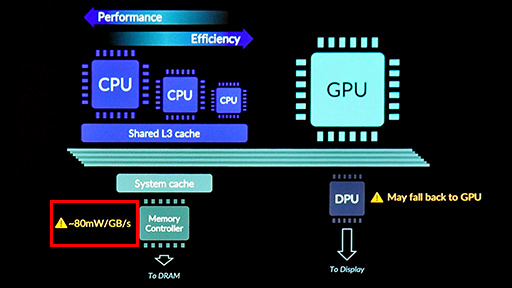
TBRは,「Zバッファを持たないレンダリング手法」と呼ばれることが多い。しかし実際には,GPUが描画する各タイルごとに,局所的なZバッファ(深度バッファ)を持っている。
1画面まるごとではなく,各タイルごとにZバッファを持っていると理解していい。タイル単位のZバッファは,別のタイルを描画するときには初期化される。
 |
スマートフォン向けGPUは,ラインナップによってコア数が異なるが,コア数と,同時に並列描画可能なタイル数は,イコールではない。
メーカーやアーキテクチャによっても異なるし,仕様について非公開としているGPUも多いが,TBRのタイルサイズ,つまりタイル1つの解像度が16×16ピクセルなのか,32×32ピクセルなのかといったタイル解像度によっても,並列描画可能なタイル数は異なってくる。しかし,少なくともGPUコア数と同等のタイル数は並列描画可能で,場合によっては,コア数よりも多い,数倍程度のタイルを並列描画できるGPUも少なくない。
一般的にTBRでは,ポリゴンレベルの演算,すなわち頂点シェーダプロセス(※講演スライドではGeometry processingと表記)を,2段階に分けて行うことが多い。
1段階目は,3Dシーンを構成する各ポリゴンに対して,幾何学的な演算を伴った頂点シェーダを実行する。ここでは光学的な計算,たとえば頂点単位のライティングやシェーディングを行い,さらには,後続のピクセルシェーダプロセスで利用するテクスチャ座標なども,ここで事前に計算しておく。
2段階目では,頂点シェーダ適用後のポリゴンを,画面上のどのタイルで描画すべきかを判定する。といっても,ここはそれほど複雑な計算ではない。
2段階目の時点で,各ポリゴン(三角形)を構成する3つの頂点は,3D世界における3D座標(x,y,z)が決まっている。そこで,3つの頂点座標を,画面解像度に対応する2Dの画面座標(x,y)へと変換して,ポリゴンをすっぽりと囲える四角形の2D座標を求める。いわゆるバウンディングボックス(Bounding Box,BB)というやつだ。
レイトレーシングで用いるBBは直方体だが,ここは2Dなので,BBは長方形や正方形になる。
画面上における各ポリゴンのBB座標が決まれば,それらを,どのタイルで描画すべきかも確定するし,画面外に出てしまうポリゴンも決まる理屈だ。画面外に出るポリゴンは,描画対象から破棄される。いわゆる「視錐台カリング」(Frustum Culling)だ。
一般的な3Dゲームグラフィックスの場合,登場する3Dモデルは,片面(Single sided)のポリゴンを連結させて閉じた立体物として表現する。視点方向に向いてないポリゴンは,必然的に視点から見えない隠面(裏面)と判定できるので,これも描画対象から破棄できる。「隠面除去」(Hidden Surface Removal,HSR)というやつだ。なお,半透明ポリゴンの場合は話が変わってくるが,本稿では省略する。
また,視点から見て,面積がゼロとなるポリゴンも,2段階目で破棄される場合がある。
面積がゼロのポリゴンとは,たとえば三角形を構成する3頂点のうち2つが,同一の2D座標となるようなポリゴンだ。3D空間上では,ちゃんと面積があるポリゴンでも,視点との関係で2Dの画面上では線分や点になってしまうのなら,破棄するわけだ。あえて点や線分で描くケースもあるので,ケースバイケースではある。
こうした頂点シェーダプロセスの2段階目におけるカリングフェーズは,「Early Culling」(早期除去)と呼ばれることがある。スマートフォン向けGPUだけでなく,PCやゲーム機のGPUも,早期除去の機能を実装していることは多い。
ここまでのふるい分け処理を経て描画対象として残ったポリゴンは,頂点シェーダの後処理を2つ行う。
ひとつは「Attribute Shading」(属性シェーディング)と呼ばれる処理系だ。次のピクセルシェーダプロセスで利用するために,頂点シェーダから継承する属性変数などを準備するところだ。
頂点シェーダを実行することで,頂点単位の法線情報やライティング,シェーディング結果の色情報,テクスチャアドレスなどが決まる。それに加えて,実際にピクセルシェーダの実行に必要となる,テクスチャを適用するためのUV勾配や法線勾配,色勾配などのパラメータも,属性シェーディングで計算するわけだ。
これらのパラメータがすべて確定したら,描画対象となるポリゴンの頂点情報がどのタイルで描画されることになるかというTBR特有の付加情報を添えて,メモリへ書き出す。このプロセスはとくに,「Polygon List Generation」と呼ばれる。
頂点シェーダプロセスに続いては,ピクセル単位の演算であるピクセルシェーダプロセス(※講演スライドではFragment processing)へ処理が移っていく。
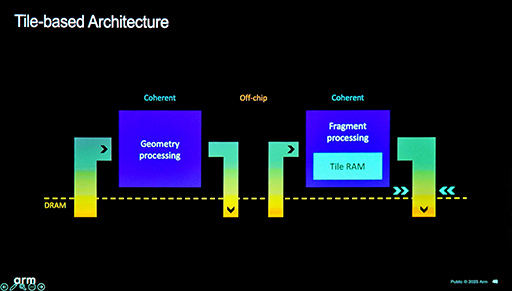 |
スライド右のFragment processing内にある「Tile RAM」は,SRAMによる作業メモリである。GPUの種類にもよるが,1タイルあたりのTile RAMの容量は,数十〜数百KBが一般的だ。Apple Mシリーズのように,数MBクラスのTile RAMを持つGPUもあるが,少数派と言えよう。
さて,ピクセルシェーダプロセスでは,頂点シェーダ処理系の最後に書き出した,どのタイルでどのポリゴンを描画するのかの対応情報(Polygon List)をメモリから読み出して,ピクセルシェーダプログラムを実行する。その作業領域がTile RAMであり,具体的な用途としては,タイル単位のフレームバッファやZバッファとして用いるわけだ。
ピクセルシェーダの稼動中は,頂点シェーダが暇になるので,別に処理を待つレンダリングパスがあれば,それらを頂点シェーダプロセスで処理する。近代ゲームグラフィックスは,多段パスのレンダリングが当たり前だ。たとえば,影生成パスや半透明エフェクト描画パスなどがある。
 |
Tile Based Renderingの長所と短所
Garcia氏は,TBRにも長所と短所があることを説明した。
 |
TBRでは,ピクセル単位のライティングやシェーディング結果の書き出し時に,ポリゴンの可視,不可視を判定する(Zテスト)場合は,各タイルごとの超高速なTile RAM上で行う。そのため,ピクセル処理における共有メモリに対するアクセスのほとんどを,隠蔽できることが長所である。
同様の理由で,アンチエイリアス処理のMultisample anti-aliasing(MSAA)でも,TBRであればメモリアクセスがほとんど必要ないのも利点だ。たとえば,「4xMSAA」の処理は,映像本体の描画解像度に対して4倍解像度のZバッファを用いて処理する。一般的なGPUでは,Zバッファをグラフィックスメモリ上に用意するので,アンチエイリアスなしと比べて,4倍ものメモリアクセスが必要である。しかしTBRなら,これらがすべてTile RAM内で動作するので,共有メモリへのアクセスは,ほぼゼロとなるのだ。
一方の短所とは何か。それは,たとえばポリゴン数が多いシーンでは,登場する全ポリゴンについて,そのポリゴンをどのタイルで描画するのかを示す対応リストの書き出し(Polygon List Generation)で,多くのメモリアクセスが発生することだ。
また,TBRのアルゴリズムでは,過去フレームを参照したり,次のレンダリングパスと依存関係を生じたりするような描画パイプラインは,高速に処理できない。特別なAPIを活用しないと,著しい描画性能低下の要因になってしまうこともあるのだ。
Tile Based Renderingの改善法 その1
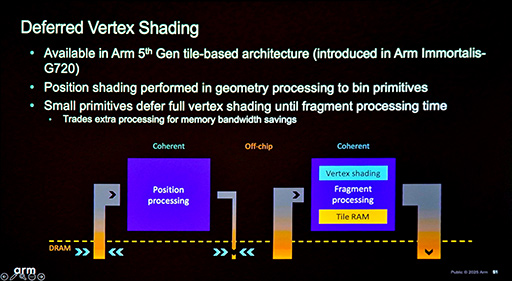
Deferred Vertex Shading
Armでは,TBRの処理系について,メモリアクセスを減らせる改善点がないかと継続的な研究を重ねた結果,3つの手法を考案したとGarcia氏は述べる。そのひとつが「Deferred Vertex Shading」だ。
Deferred Vertex Shadingは,Armの第5世代TBRアーキテクチャに採用された技術である。具体的には,ArmのGPU IP「Immortalis-G720」で初めて実装された。
まず,Armのスタッフが注目したのは,どのタイルで描画するのかというTBR特有のPolygon List Generationによるメモリアクセスの多発だ。
そもそも,頂点シェーダプロセスを経てPolygon Listを生成して,それをピクセルシェーダプロセスで再び読み込むのは,なんとも冗長だ。頂点シェーダプロセス冒頭で,ポリゴン情報をメモリから一度読み込むことは避けられなくとも,Polygon List Generationをもう少し最適化できないかと,Armのスタッフは考えたようだ。
そこで,注目したのが,Early Cullingを経て描画対象として確定した3Dモデルにおける,各ポリゴンの大きさだ。
画面の広い範囲に表示される大きなポリゴンは,多数のタイルにまたがって描画することになるので,並列でのタイル描画では,メモリ側にあるPolygon Listに対して,同じポリゴンの情報を何度も参照する。つまり,キャッシュメモリの利用率が上がるはずだ。
そもそも,フィルレートを計測するベンチマークソフトでもない限り,大きなポリゴンを画面上にたくさん描画するケースは少ない。つまり常識的には,Polygon List Generation上に大きなポリゴンの情報が含まれることはあまりないので,メモリアクセスは限定的とみなせるだろう。
そこで,大きなポリゴンについては,従来どおりのTBRの仕組みで描画する。Attribute Shadingも行って,Polygon List Generationにも含めるわけだ。
 |
逆に,小さなポリゴンはどうするのか。小さなポリゴンは,必然的にそれほど多くのタイルにまたがることはないと考えられる。またがったとしても,隣接するタイル同士が対象となるだろう。並列タイル描画が行われているなら,L2キャッシュやL3キャッシュ(ラストレベルキャッシュ)が効きそうだ。
そこでArmでは,小さなポリゴンについては,Polygon List Generationに含めない,という大胆な判断を下した。
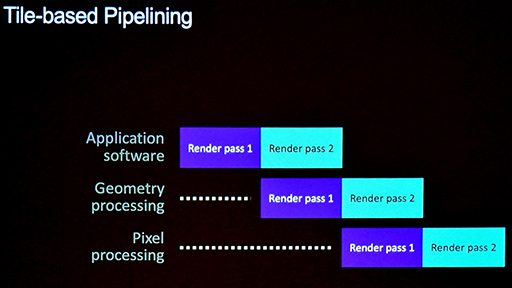
つまり,ピクセルシェーダプロセスの冒頭で,もう1回,頂点シェーダプロセスをやり直すということだ。先のスライドにおける右側のフローが,その流れである。
スマートフォン向けGPUは,半導体プロセスの進化に合わせて性能が上がっているものの,メモリアクセス(=消費電力)を節約する必要は,今も昔も変わらない。そうであるなら,メモリアクセスの節約を優先して,頂点シェーダプロセスをもう一回やり直したらどうなるか,試してみたというわけだ。
Garcia氏も,「メモリアクセスによる電力消費と演算による電力消費を天秤にかけた結果の判断」という意図を述べていた。おそらくArmの実験で,この判断でいけそうだと,確信できるシミュレーション結果が得られたのだろう。
もちろん,ここまで大規模なアーキテクチャ改変は,過去のGPUと比較して,キャッシュメモリやTile RAMの容量を大きく取れるようになったことも後押しになったとは思う。
 |
 |
繰り返しになるが,Deferred Vertex Shadingは,ピクセルシェーダプロセスの冒頭で行われるのが特徴的だ。これは,ArmのDeferred Vertex Shading対応GPUならではの専用設計である。ほかのGPUで真似ようとしても,簡単にはできないところだ。
Garcia氏は,Deferred Vertex Shadingにおけるもうひとつの大きな利点として,インスタンス描画されている3Dオブジェクトが,Polygon List Generationに展開されない点を挙げた。
たとえば,森を描画するシーンを想定してみよう。Early Cullingで破棄されることなく,1万本の樹木が描画対象に選ばれたとする。そして,樹木1本の3Dモデルは,1000ポリゴンだとしよう。
こうしたケースの3Dゲームグラフィックスでは,樹木は同じ3Dモデルを使い回すことが多い。1万本を描画するには,同じ3Dモデルを参照して,1本ずつ描画するたびに,幹の背丈を変えたり,枝の角度を変えたり,もっとシンプルに向きを回転するといったパラメータ調整で,異なる樹木を描画しているように見せる最適化(という手抜き)を行うものだ。一流CG映画スタジオのPixar Animation Studiosでも行っているテクニックである。
このテクニックを「インスタンス描画」(Instanced Draw)と呼ぶのだが,これによって,GPUが描画時に読み出す3Dモデルは,樹1本分の1000ポリゴンで済む。ところが従来のTBRでは,1000ポリゴン×1万本で1000万ポリゴン分のPolygon List Generationを行っていた。まるで圧縮されたデータを展開しているかのようだ。この場合,Polygon List Generation時のメモリアクセスが大幅に増大してしまう。
しかしDeferred Vertex Shadingでは,Polygon List Generation時にインスタンス描画の展開を行わないので,メモリアクセスを大幅に減らせるわけだ。インスタンス描画用の頂点シェーダプロセスは,ピクセルシェーダプロセス側のDeferred Vertex Shadingで,普通のGPUのように逐次実行されので,樹1本分の1000ポリゴンは,ラストレベルキャッシュに載ると期待できる。
Deferred Vertex Shadingがもたらすインスタンス描画の恩恵は,オープンワールド系の広大なゲームフィールドを表現するゲームと,相性がよさそうだ。
 |
Tile Based Renderingの改善法 その2
Hidden Surface Removal
TBRにおける2つめの改善点は,ピクセルシェーダプロセス側にある。
ラスタライザが,ポリゴンをピクセル単位に分解する。その各ピクセルに対して,ピクセルシェーダプログラムが,ピクセル単位のライティングやシェーディング,テクスチャマップを適用する。ここまではTBRでも同じだ。各タイルでの描画工程は,Tile RAM上で行われて,最終的に確定したタイルの描画結果を,共有メモリに反映する流れとなる。
ここでの大きな問題は,描画する必要のないピクセルに対しても,ピクセルシェーダが動作してしまう点だ。
視点に近い位置のポリゴン「A」を描画したあと,次に描画するポリゴン「B」が,ポリゴンAの後ろ側に存在する場合を考えよう。ポリゴンBを構成するピクセルに対して,ピクセルシェーダで処理して色が確定したとしても,すでに手前にあるポリゴンAのピクセルが描画済みならば,そこに上書きするわけにはいかない。もし描いたら,前後関係がおかしい画像になってしまう。
ピクセル単位の前後関係(遮蔽関係)を判断するには,Zテスト(深度テスト)を行うのが,GPUの種類によらず定石である。違いは,一般的なGPUでは,Zテストを共有メモリ側に展開したZバッファ上で処理するが,TBRでは,Tile RAM内に設けた局所Zバッファで行うことだ。メモリアクセスがないTile RAMならではの利点だ。
しかし,遮蔽されて本来は見えないピクセルに対しても,ピクセルシェーダが動作してしまうのは,TBRでも変わらない。
この問題による悪影響を軽減すべく,ArmのGPU IP「Mali-T620」以降では,ピクセル単位の隠面除去(HSR)機構を搭載しているのだ。
先述したHSRは,頂点シェーダプロセス側で行われるポリゴン単位のHSRで,具体的には視点方向に向いていないポリゴンを除去するものだった。一方,ピクセル単位のHSR処理は,「Early ZS Test」(Zは深度,Sは型抜きステンシル)とも呼ばれる。
Mali-T620以降が備えるピクセル単位のHSRは,ラスタライズの段階で,ピクセル単位の深度を先に求めてしまうことで,このピクセルは遮蔽されているか,いないかの判断を,ピクセルシェーダの実行前に行う。これにより,ピクセルシェーダの無駄な動作を減らせるだろうという算段だ。
とはいえ,この工夫も完璧ではない。たとえば,順不同でポリゴンを描画していく過程で,後から描画するポリゴンが,先に描画されたポリゴンよりも視点に近い位置にある場合,最終的に表示されるのは,視点に近い側のポリゴンだけである。
すでにいくつかのポリゴンが描画済みの領域に,後から別のポリゴンを描画した場合,上書きされた領域を計算したピクセルシェーダプログラムは,無駄に実行されたことになる。
 |
 |
Garcia氏は,「このテクニックの効果が,近年は薄れてきた要因は,ほかにもある」と述べる。最近は,映像フレームの解像度がフルHD(1920×1080ピクセル)以上となることが多く,TBRのタイルサイズも大きく(≒タイル解像度も高く)なってきた。3Dモデルも多ポリゴン化したことで,1ポリゴンあたりのサイズは小さくなっている。つまり近年は,ピクセル単位のHSR処理は無駄ではないものの,この処理によって無駄にならないピクセルは,昔ほど多くないというのだ。
さらに,近代的なゲームグラフィックスでは,半透明テクスチャや,透明要素と不透明要素の両方からなる葉や金網のようなテクスチャを適用するポリゴンの割合も増えてきた。そのため,HSR処理自体が無駄になるケースも増えてきたそうだ。
Tile Based Renderingの改善法 その3
Fragment Prepass Hidden Surface Removal
一般的なGPUで動作する3Dゲームグラフィックスでは,ピクセルシェーダの無駄な動作を減らすために,深度情報の先出しと呼ばれるテクニックを活用することがある。本セッションでGarcia氏は,「Depth Prepass」と呼んでいたが,業界的には「Z-Prepass」と呼ばれることも多いテクニックだ。
Depth Prepassの発想はシンプルである。3Dシーンのポリゴン描画を2度も行うのだが,1度目の描画では,画面に表示する映像を描画するのではなく,ピクセルシェーダプログラムを走らせず,Zバッファの更新だけを行う。
2度目は,普通にピクセルシェーダプログラムを実行して映像を描画するのだが,ここで先述したピクセル単位のHSR処理であるEarly ZS Testを行うだけで,無駄な動作を完璧に抑えられる。
1度目の描画におけるZバッファの更新は,画面に見えるすべてのポリゴン(≒ピクセル)からなる深度情報なので,2度目の描画では,あとから別のポリゴンに上書きされることがないからだ。
 |
しかしGarcia氏は,「これは上手いアルゴリズムだが,ソフトウェア的なテクニックでしかない。そもそもZバッファを保持し続けることが前提のアルゴリズムは,TBRでは望ましくない」と指摘する。そのうえでGarcia氏は,「我々は,ハードウェアの力でDepth Prepass的なテクニックをTBRで実現する新機能を,GPUの『Immortalis-G925』に搭載している」とアピールした。
 |
Immortalis-G925で実装されたピクセル単位のHSR処理,すなわちピクセルシェーダの無駄な動作を抑止する技術は,「Fragment Prepass Hidden Surface Removal」(以下,Fragment Prepass HSR)と呼ばれる。
Fragment Prepass HSRでは,Depth Prepassのために3Dシーンを2回描画する必要はないが,ピクセルシェーダプロセスを2段階に分けて実行するという。Fragment Prepass HSRのパイプラインが,次のスライドになる。ここからの説明は,このスライドをもとに進めていく。
 |
ピクセルシェーダプロセスの1段階目は,「Prepass」と呼ばれる。ここでは,まずポリゴンをピクセルにラスタライズして,Early ZS Testにかけるこの流れは,Mali-T620以降のGPUと同じだ。
ここのHSR処理で,処理対象のピクセルが破棄されると,Mainpassへ進む。破棄されなかったピクセルは,Fragment Prepass HSR特有の処理系である,Fragment Prepass Shaderへと進む。
Fragment Prepass Shaderは,事実上,Depth Prepassを行う処理系で,ピクセルシェーダプログラムを実行するが,ピクセル色を計算するライティングやシェーディング,テクスチャ処理は行わない。
その結果として,通常の描画時のように,ピクセル単位のZテストをTile RAM上の局所Zバッファで行う(Late ZS Test)。遮蔽されていないから描画すべきと判断されたら,Tile RAMの上の局所Zバッファを更新する。フロー図中の「Update Visibility」が,このプロセスだ。
ピクセルシェーダプロセスの2段階目「Main pass」は,通常の描画におけるピクセルシェーダプロセスに相当する。もう一度最初からピクセルシェーダプロセスを行うようなものなので,ラスタライズから始まる。
スライドのMain passは,だいぶ省略されているが,ここでもラスタライズしたピクセルに対して,必要に応じてピクセル単位のHSR処理を行う。たとえば,Prepassを通らなかった例外的なプリミティブなどが対象となる。
Main passでのピクセルシェーダプログラムは,Prepassでは実行しなかったピクセル色の算出に関わるライティングやシェーディング処理も行う。
この技術のポイントは,Fragment Prepass Shaderによって,Depth Prepassを,一度の3Dシーンで描画してしまうことと,これによってピクセルシェーダの無駄な動作を完璧に排除できることだ。
なお,特殊なピクセルシェーダプログラムを適用すべき材質や,そもそも特殊なプリミティブ(三角形以外のポリゴンなど)は,Fragment Prepass HSRでは手に負えない。その場合は,Mainpassで普通の手順により描画すればいい。このケースでは,Mali-T620世代と同様に,ピクセルシェーダの無駄な動作は生じてしまう。
 |
Garcia氏によれば,そうした例外事例は,スマートフォン向けゲームグラフィックスではそうそうはないので,多くの場合はFragment Prepass HSRの恩恵が得られるそうである。
マニアックなエンジニアリングの面白さがあるスマートフォン向けGPU
スマートフォン向けGPUのアーキテクチャ詳細を,GPUメーカーの設計者が登壇して,ここまで詳しく解説することはあまりない。GDC 2025におけるGarcia氏のセッションは,非常に希な機会だったと言える。筆者にとってもかなり参考になった。
最後にGarcia氏は,スマートフォン向けGPUにおいて,性能を向上させやすい頂点バッファの持ち方を紹介した。それは,3Dモデルを構成する頂点データやその付随情報を,登場するポリゴン順では記述しないフォーマットにすることだ。
Garcia氏が推奨するのは,頂点座標データのみを登場ポリゴン順にまとめたストリーム(頂点バッファ)と,同様に付随情報だけをまとめた別のストリームの2本に分けて管理する方式だ。
スマートフォン向けGPUのキャッシュラインはサイズが小さく,32byteから,多くても64byte程度だ。たとえば,あるゲームで,以下のスライドのようなフォーマットを採用していたとしよう。
 |
仮に,各パラメータによく用いられる数値形式と,要素数を以下のように仮定すると(※実際はゲームごとに異なる),1頂点あたりデータ総量は30byteとなる。
- Position:FP32×3要素=12byte
- Tangent:FP16×4要素=8byte
- Normal:FP16×3要素=6byte
- Tex coord:FP16×2要素=4byte
しかし,これだとキャッシュラインが32byteの場合は1頂点分だけ,64byteでも2頂点分しかキャッシュできない。
そこで,Garcia氏が推奨したように,Positionだけを分離して2ストリーム化すると(※上図の右),キャッシュラインが32byteのケースでも,32byte÷12byteで2頂点を,64byteなら5頂点をキャッシュできる計算だ。
TBRでは,ポリゴンとタイルの割り当て対応を求める演算時や,Immortalis-G720以降で使えるDeferred Vertex Shading時には,頂点座標のPositionを高頻度で参照する傾向にある。Garcia氏推奨の2ストリーム式のほうが,メモリアクセスをさらに隠蔽できる可能性が高まるだろう。
メジャーなゲームエンジンでは,このような最適化を自動で行ってくれるのかもしれないが,面白いテクニックではなかろうか。
 |
- 関連タイトル:
 Mali,Immortalis
Mali,Immortalis
- この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー